

How Does Simple Semantic Caching Work?
For simple, context-agnostic semantic caching, take the user query and perform a vector search on the cache to find what is essentially the same query – even if the user query phrasing is different. If a match is found in the semantic cache, return the response from the semantic cache rather than calling the LLM. A semantic cache hit has a faster response time and costs less compared to an LLM.
In the first conversation, the user asks new questions, the LLM responds, and the cache gets populated.
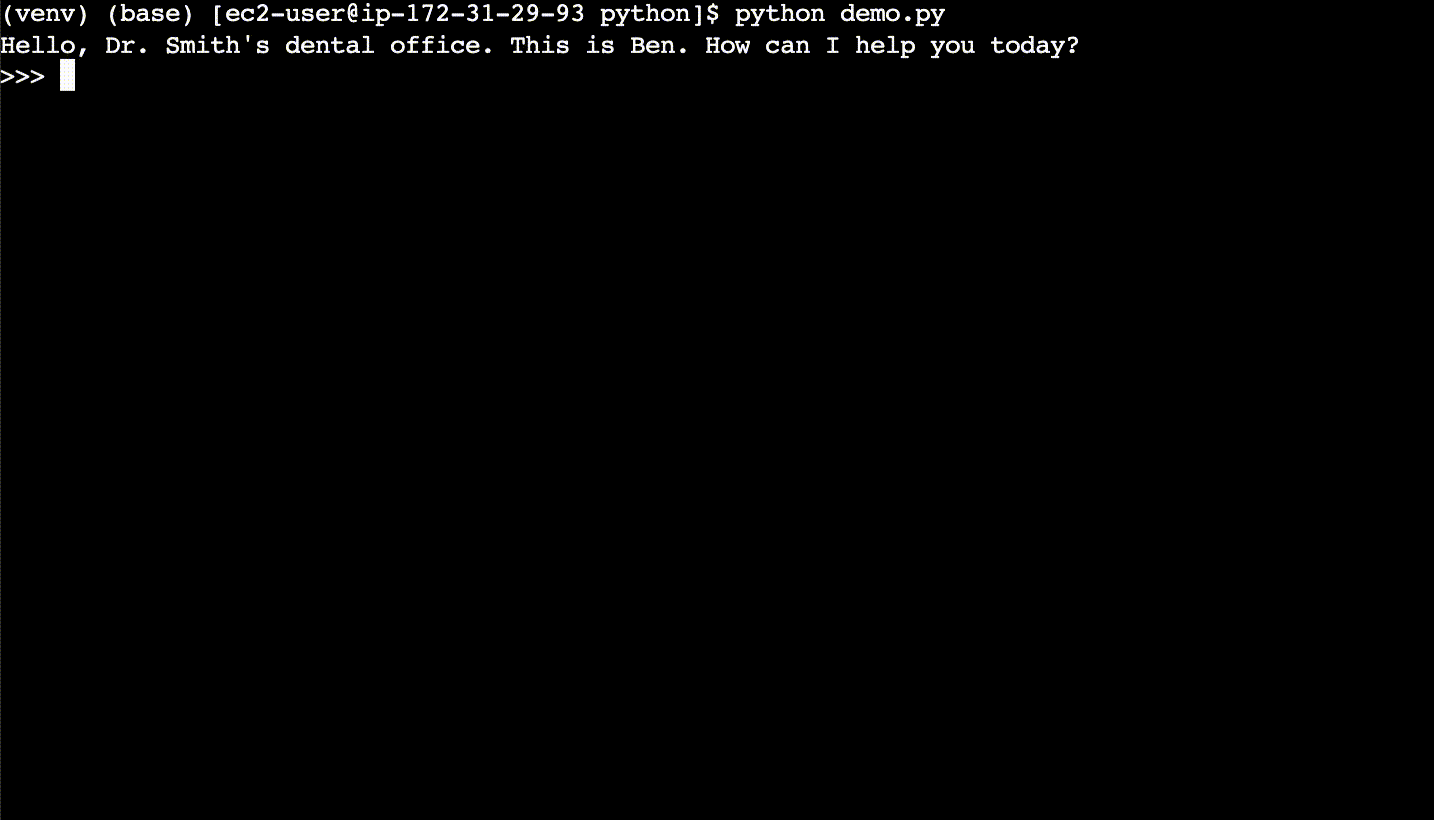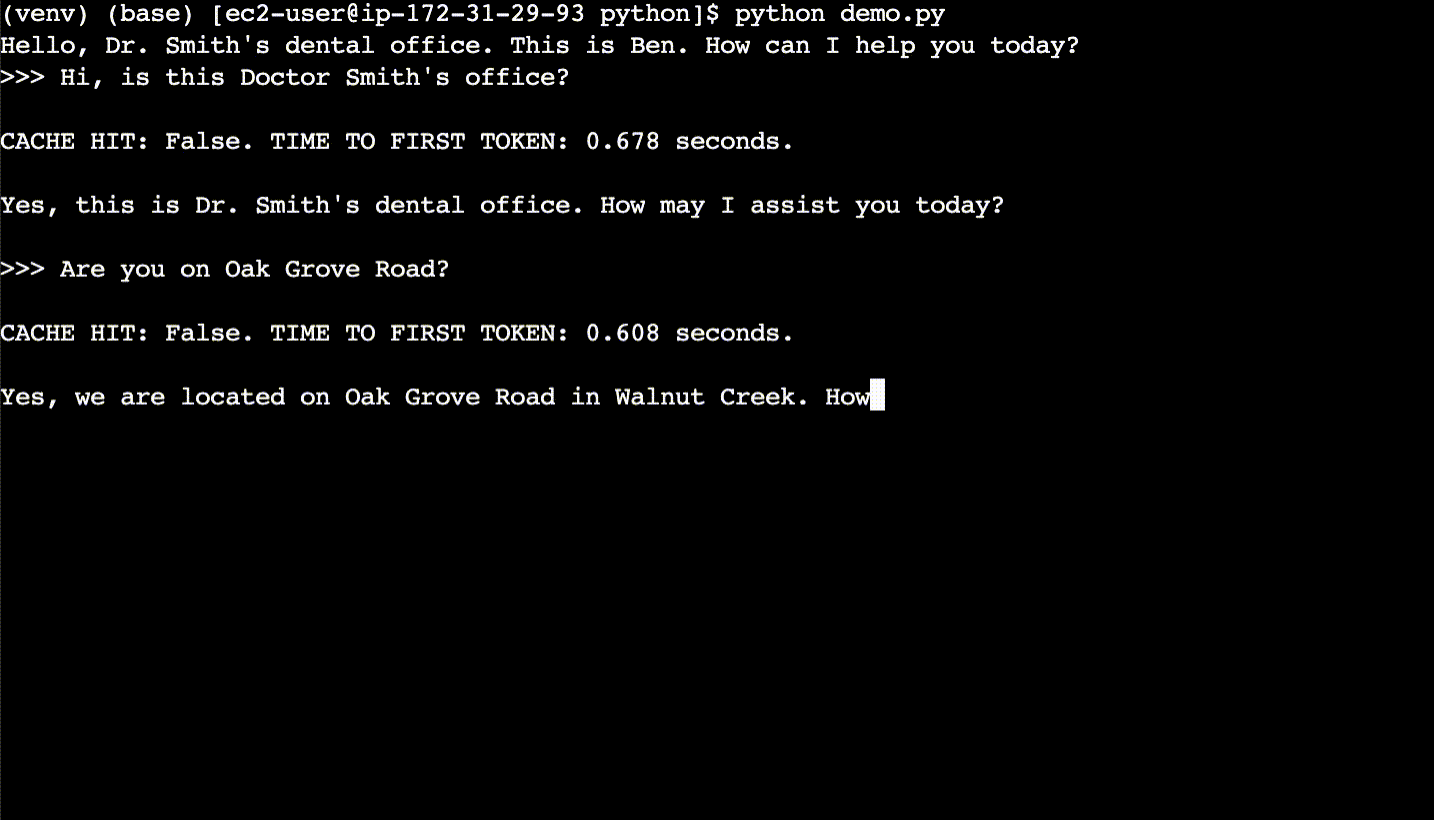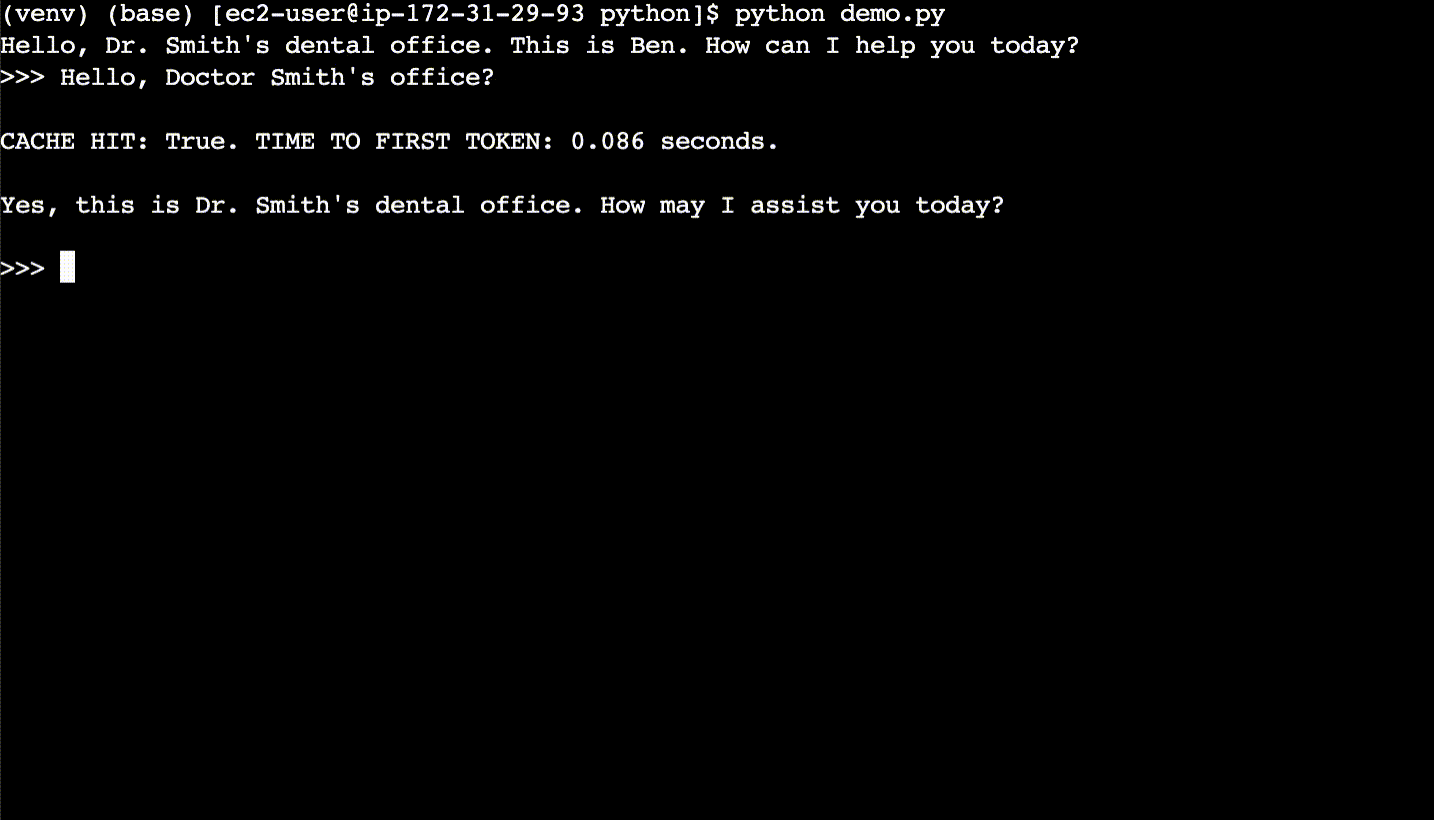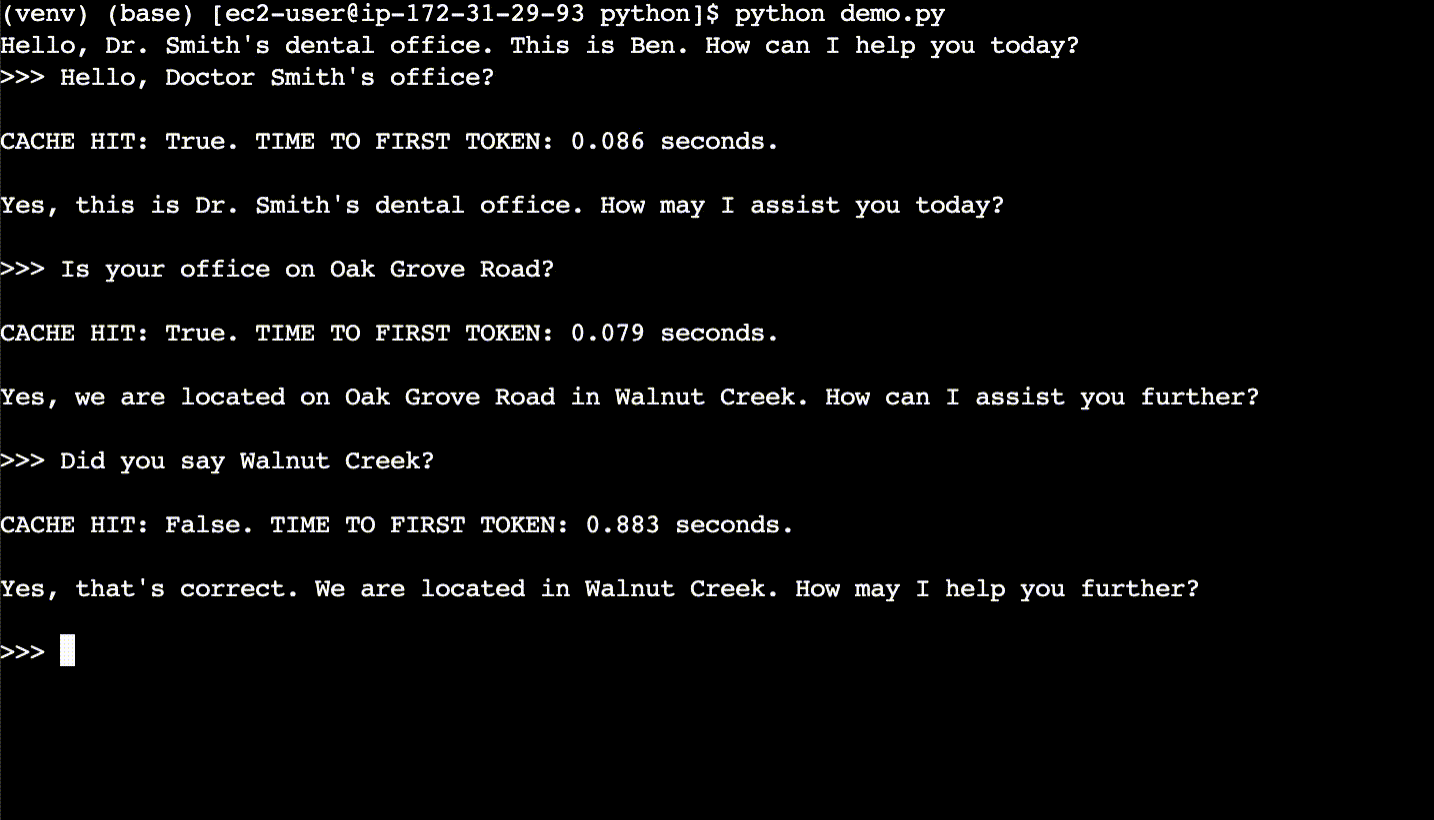
In the second conversation (after the terminal is cleared), the user asks the same questions, but with different phrasing. The responses are returned from the semantic cache and the time to first token is ~10x faster.
Doesn't My Vector DB Have A Semantic Cache?
We’ve talked to many developers who try semantic caching with a simple cosine similarity search (like the ones that come with vector databases), see the unsurprisingly poor accuracy from this context-agnostic approach, and kick the can on LLM caching’s cost and latency improvements.
An accurate and effective LLM cache needs to understand the context of the conversation with the user. It’s lifetimes of work. Lifetimes that AI developers should spend building their core user product rather than infrastructure.
Canonical AI Context-Aware Semantic Caching
- High Precision Semantic Caching. For conversational AI (i.e., Voice AI agents), get cache hits only when it's contextually appropriate.
- High Recall Semantic Caching. For many AI applications, the Canonical AI Cache hit rate is above 20%. Even in open-ended conversations without much repetition, our cache gets hits in the beginning and end of a session. The first and final impressions are critical for user experience.
- Fast Semantic Caching. Response times are ~50 ms for on-prem deployments and ~120 ms for over-the-network.
- Secure Semantic Caching. Personally Identifiable Information (PII) is never cached so user data is safe.
- Tunable Cache Temperature. You decide whether you want a cache hit to return the same response or differently phrased responses.
- One Call For Caching and Knowledge Retrieval. On cache misses, we retrieve knowledge (i.e., the R in RAG), which you augment and return to the user.
- Simple Integration. Deploy our LLM Cache one step upstream of your LLM call. If there’s a cache hit, don’t call your LLM. If there’s a cache miss, then update the semantic cache with the LLM completion after you’ve responded to the user. It's easy!
Pricing
Free Tier
If you have less than 10k of input and output tokens on your cache hits per month, Canonical AI Cache is free.
Paid Tier
If you have developers with 10k of input and output tokens on cache hits per month. We charge only for cache hits. On cache hits, we charge 50% of the per token price of your LLM model.
Try It Out!
You can try out our context-aware semantic cache with our Colab notebook.
Or generate an API key using the link above for a free two-week trial! Our examples on GitHub can help you get started.
Questions? Check out our semantic caching FAQ. Or email us! We'd love to hear from you!