How to Prevent LLM Hallucinations with Semantic Caching

The primary problem with Generative AI quality is getting the Large Language Model to answer correctly. Sometimes you need an exact response from your LLM application. For example, your app may require a specific answer to questions about a store’s hours of operation, or an airline’s refund policy, or something from your website’s FAQ. In these cases, you don’t want the model to hallucinate.
LLM Hallucinations
What is an LLM hallucination? An LLM hallucinations is when the model produces nonsensical output, factual inaccuracies, misleading information, or more broadly speaking, something you didn't explicitly instructed the LLM to say.
Why do LLMs hallucinate? The underlying cause is that machine learning models are inherently non-deterministic. As our friend Zach Koch, CEO of Fixie.ai, likes to say, “All LLMs do is dream. In a sense, everything is a hallucination.”
Ultimately, if we want to eliminate non-determinism, then we have to eliminate the model.
Semantic Caching
Semantic caching is a method to prevent LLM hallucinations. A semantic cache is like a dictionary of question-answer pairs (i.e., key-value pairs) that sits in front of the LLM. Here is how semantic caching works.
Semantic Caching Steps

- When a user makes a request, the code first searches the semantic cache for questions with the same intent.
- If a question with the same intent is found in the cache, regardless of how it was phrased, then send the answer from the cache to the user.
- If the question is not found in the cache, then send the query to the LLM and send the LLM response to the user.
- After sending the LLM response to the user, update the cache with the user query and the response. That way, the next time someone asks the same question, the code can return the answer from the semantic cache.
LLM developers love semantic caching because they improve AI performance and reduce cost. A cache hit has a faster response time (~50 ms if self-hosted) and costs less compared to calling a LLM. Semantic caching can also be used to prevent hallucinations and improve AI quality.
How to Prevent Hallucinations with Semantic Caching
To prevent LLM hallucinations with semantic caching, you don’t let the LLM populate the semantic cache over time. Instead, you pre-populate the semantic cache with a set of questions and predetermined answers. When the user asks one of those questions, even if the phrasing is different, then the cache returns the predetermined answer – rather than the returning an answer from the dreaming LLM.
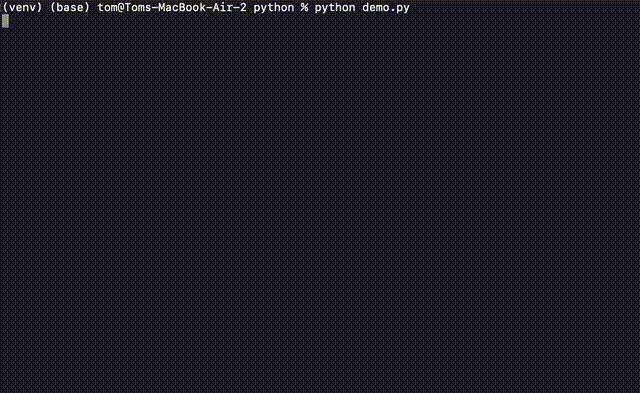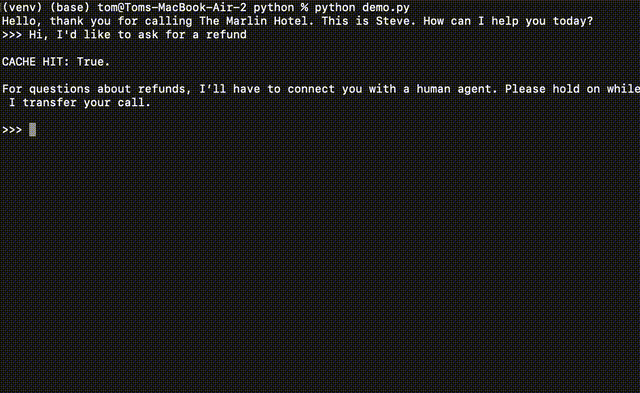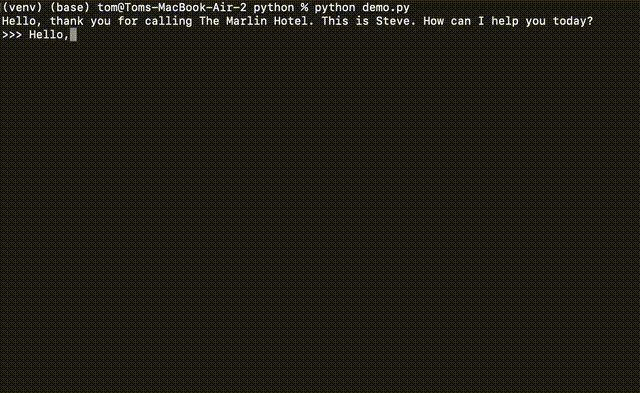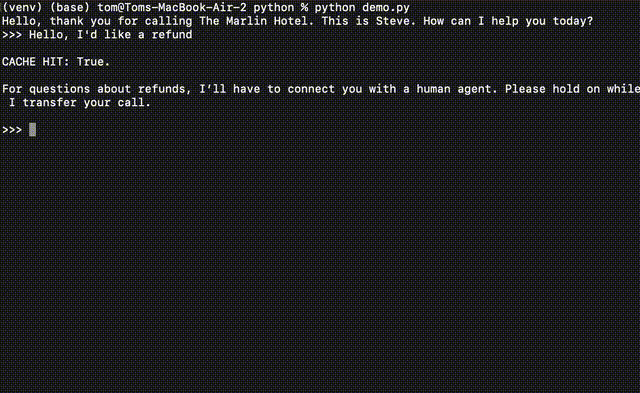
For example, let's say you are building a customer support Voice AI. When a user asks about a refund, you may want the AI to transfer the call to a human agent. You would pre-populate the semantic cache such that whenever someone asks about a refund, the LLM response is, "For questions about refunds, I’ll have to connect you with a human agent. Please hold on while I transfer your call."
In a sense, it's a rethinking of the modern Voice AI. In traditional rule-based Voice AI systems, like Amazon's Lex, the developer creates an intent (i.e., schedule_appointment) and then explicitly lists every permutation of how someone may state they want to schedule an appointment. The intent-based systems use machine learning technologies like recurrent neural networks to flesh out the list of utterances, but the intent-based systems still get stumped by unexpected requests. By adding a semantic cache to a modern LLM-based Voice AI, you get the benefits of intent-based systems and the ability to handle the unpredictability of real people.
But wait, won’t that make my AI sound robotic?
The spontaneity that arises from non-deterministic LLMs is what makes them seem more human. For your user experience, you may want the LLM to respond in a cerain way, but not with the exact same phrasing each time. After all, people don’t answer the same question in the same way every time.
By providing more than one value for each key in the cache, you can introduce randomness while still adhering to the required responses. In an analogy to the temperature setting on an LLM, we call it semantic cache temperature.
At a semantic cache temperature of zero, there is only one value for each key. On a cache hit, there is only one possible answer that gets returned to the user from the cache.
As the semantic cache temperature increases, the number of values associated with each key also increases. On a cache hit, the code randomly picks from the list of predetermined answers. In effect, the AI doesn’t repeat itself verbatim in a robotic way, but it still sticks to its script.
Although this wouldn’t be helpful for reducing hallucination, you can take this one step further. At the highest semantic cache temperatures, you can introduce even more randomness into the responses by occasionally bypassing the cache. That is, on some percentage of cache hits, the code skips over the cache and sends the query to the LLM.
Isn’t This Why They Invented RAG?
If it’s mission critical that a user query gets a specific response, then short-circuiting the model with caching will ensure that you don’t get a LLM hallucination. The LLM can’t hallucinate if you don’t call it.
For cases where you need the LLM to respond from a data set and it’s acceptable if the model is sometimes wrong, Retrieval Augmented Generation (RAG) is a common method. In RAG, you first semantically search a knowledge base for subsets that are relevant to the user query. Next, the subsets are passed to the LLM to generate a response to the user query.
The advantage of RAG over semantic caching is you don’t have to thoughtfully pre-populate each cache entry. The disadvantages of RAG are in latency and cost. RAG is slower and more expensive than caching because you have to retrieve the information from the knowledge base and pass it to the LLM.
Quick note: Generally, if a developer needs caching, they may also need RAG. We’ve built RAG into our caching layer. If the customer uploads a knowledge base, then, on cache misses, we run retrieval on the knowledge base and return content to the developer.
Try Out Semantic Caching!
Semantic caching is an effective method to reduce AI hallucinations. For cases where you need the LLM to respond in a specific way, then send the user query to a pre-populated cache rather than sending the query to the non-deterministic LLM. If you prevent LLM hallucinations in scenarios where you want deterministic behavior from your LLM application, then it will improve your LLM application quality.
If you’d like to try semantic caching to prevent LLM hallucinations, generate an API key on our homepage and follow the GitHub examples to get started. Or just reach out! We would love to meet you!
Tom and Adrian
April 2024