Reduce Voice AI Latency With Semantic Caching

We work with founders who have been building Voice AI for years. They have built Voice AI using each new wave of technology. Through each technological iteration, the Voice AI kept falling short of user expectations. Arj Vasan, CTO of Voicebite.ai, has built Voice AI for Drive-Thrus at three companies.
"When GPT-4 was released", he said. "Everything changed for Voice AI."
Open-ended, off-script, spontaneous interactions, like the sort that real humans have, no longer confound the AI. With the arrival of Large Language Models like GPT-4 and Claude 3, voice and multimodal AI will eat the world.
But first, we have to address latency.
Voice AI Latency
Latency is the primary driver of Voice AI quality. When people talk to each other over the phone, they expect a response in about 400 milliseconds or less. When the AI takes too long to respond, the user knows they’re talking to a machine and the user experience is dead. People are much less patient and less forgiving of mistakes with machines compared to people. Low latency is quality.
The ability of GPT-4 and Claude 3 to handle unpredictable and open-ended input is what unlocks the potential of Voice AI. The less sophisticated models, like GPT 3.5, are insufficient. The powerful models are required for Voice AI, but they’re slow. Based on this entertaining and insightful analysis by the founders at Credal.ai, the Time-To-First-Token for GPT-4 is untenably slow. Time to first token in seconds doesn’t make for an uncanny user experience.
Semantic Caching
Fortunately, we don’t have to call the lumbering LLM every time. With semantic caching, we reuse previous LLM responses.
Here is a basic description of a simple semantic cache. For each new user query, the code first semantically searches the cache for what is essentially the same query – even if the query phrasing is different. If a match is found in the cache, the code returns the answer from the cache rather than calling the LLM. Cache hits have faster response times and cost less compared to calling a LLM.
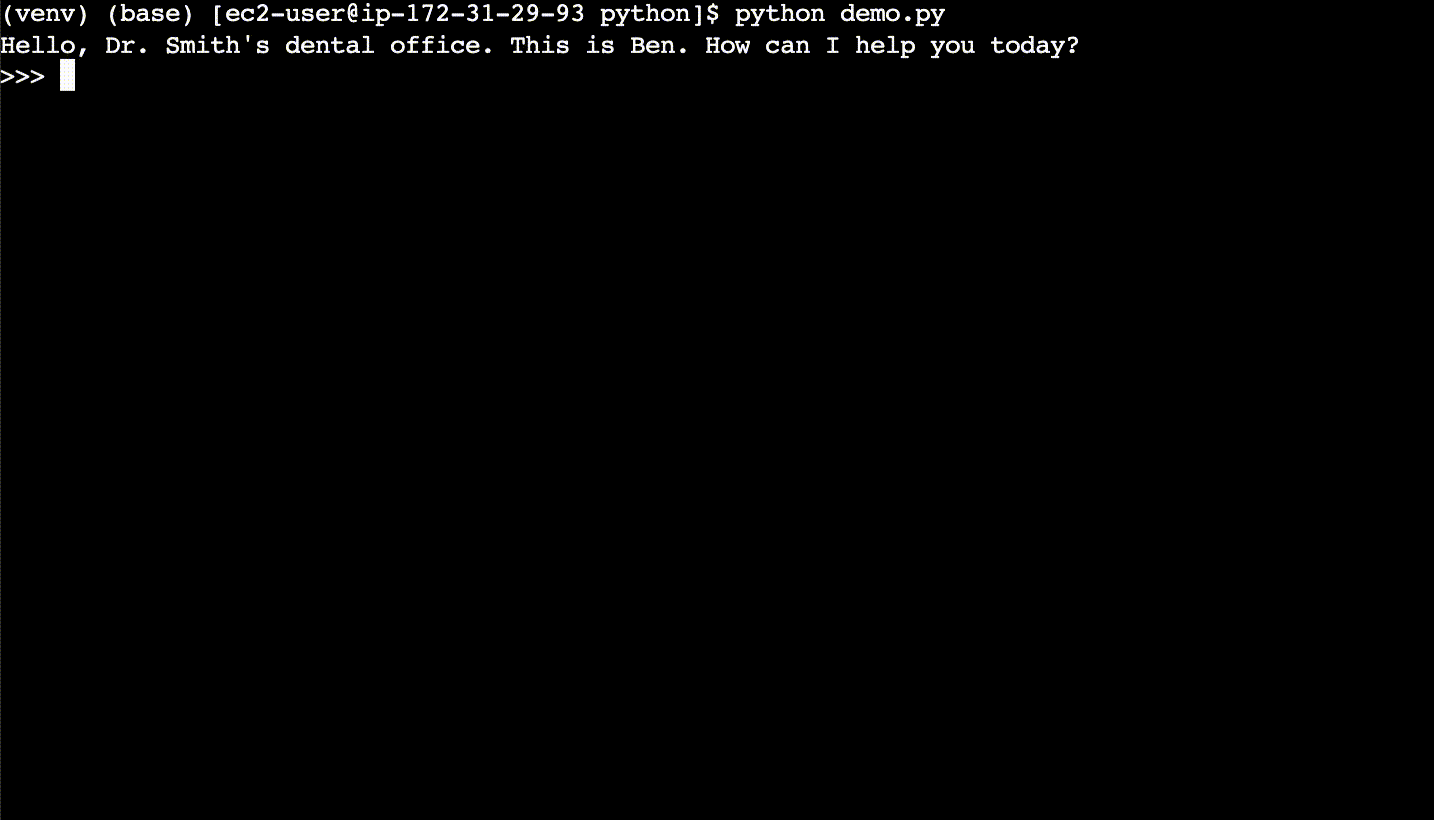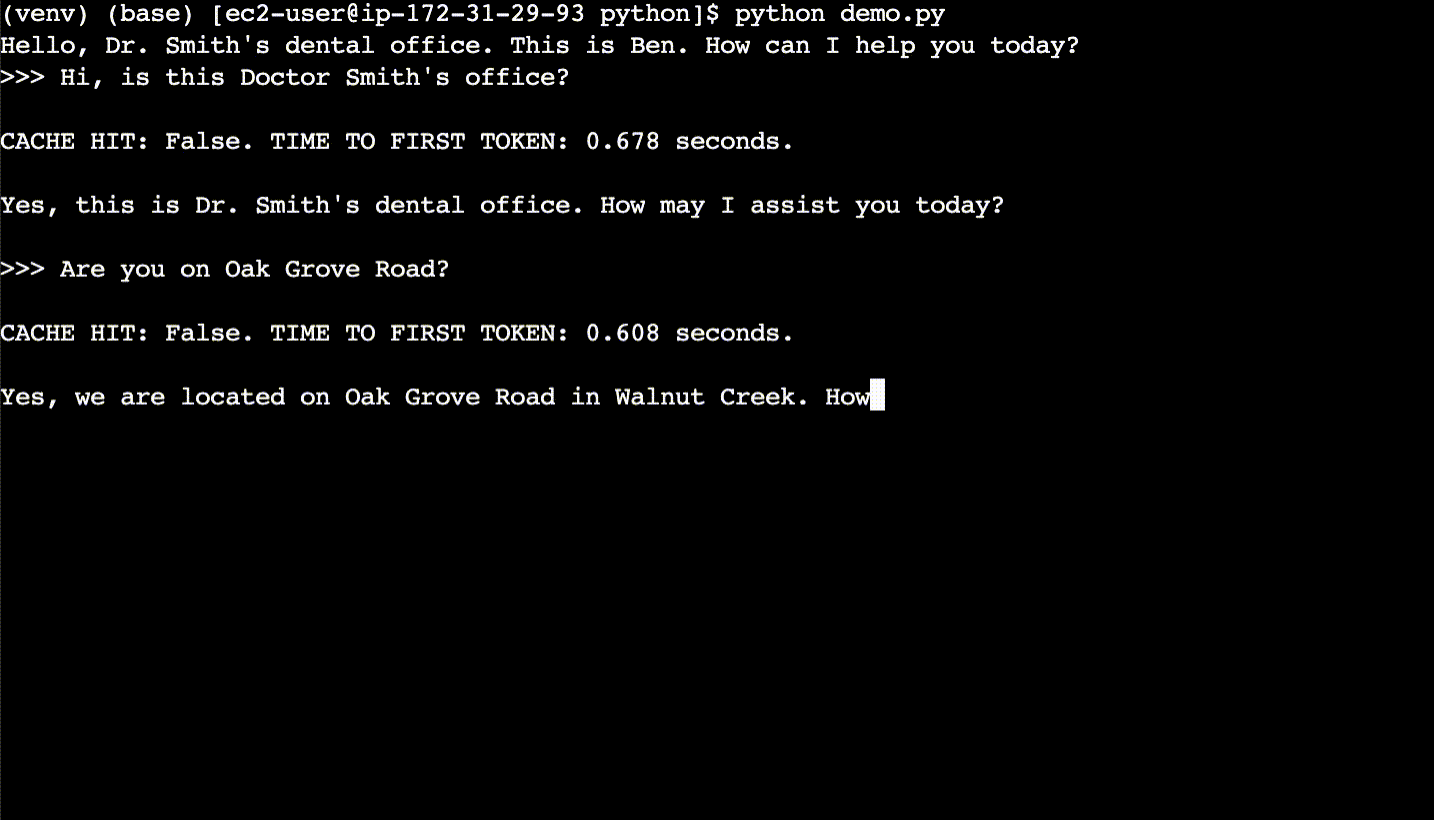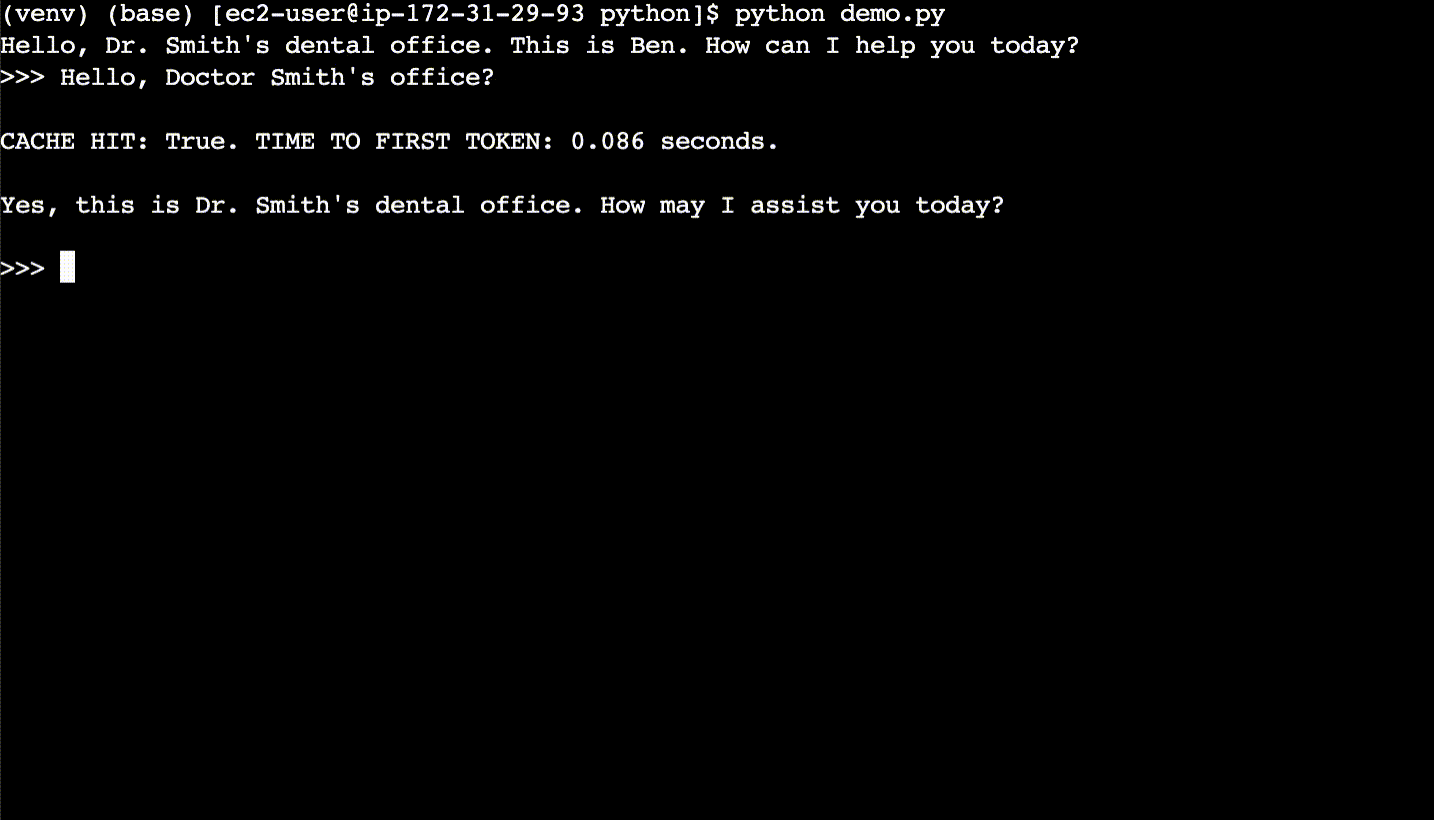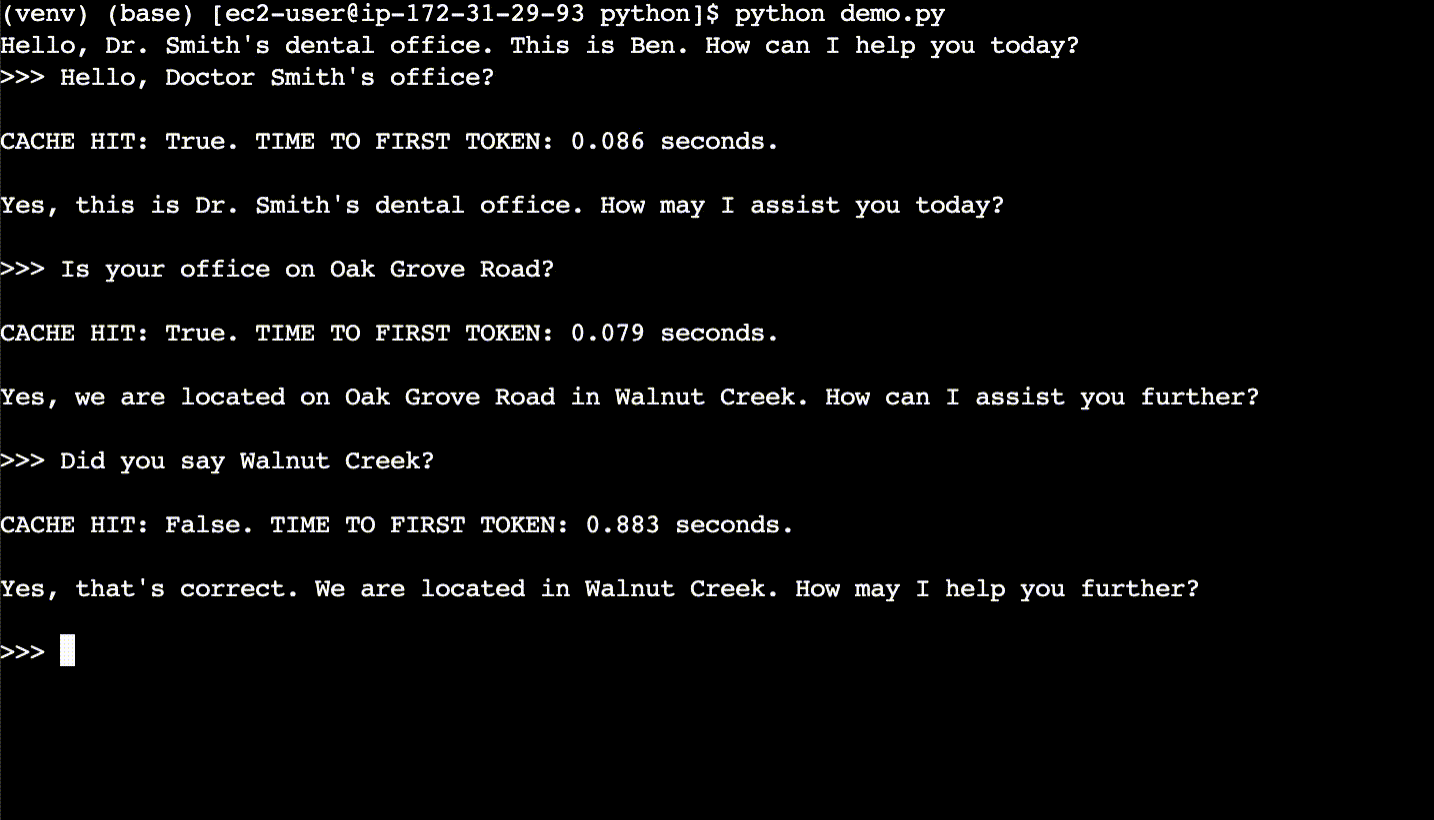
In the above example, the cache is first populated with LLM responses. After the CLI session is cleared, then the new user queries are found to be cache hits, despite different phrasing. The cache hits return responses ~10x faster than the LLM.
How Does Semantic Caching Work?
Here's a guide to a simple, context-agnostic semantic cache (i.e., LLM cache, prompt cache). A simple semantic cache performs a vector search to find the semantic similarity between the new user query and the previously stored user queries.
First, the user query and the cached query are transformed into embeddings.
Next, the two embeddings are compared using cosine similarity to evaluate how closely related the two queries are in terms of their meaning. You don't need the new user query and the cached query to have the exact same wording. Instead, you're using the relationship between the embedding representation of the queries to see if the two queries are sufficiently similar.
Finally, if the two queries are sufficiently similar in the embedding space, then you can assume they're the same question and return the response from the cache.
The Challenges of Conversational LLM Caching
For simple question and answer AI apps (e.g., a Retrieval Augmented Generation app for a knowledge base), especially those where the user only has one or two turns per session, semantic caching is easy. You don’t have to worry about two user queries having the same meaning but referring to two different things. It takes a sophisticated approach to semantic caching to get accurate cache results in conversational applications.
For conversational AI, the cache needs to know about the context of the user query. For example, a user may ask a question about something in the beginning of a conversation, then ask the very same question about a different matter later in the conversation.
Let’s look at the following example.
LLM: Would you like to learn more about the cushion?
User: Yes, how much does it cost?
LLM: $10
User: Ok. Tell me about that metal bowl?
LLM: You mean the singing bowl?
User: Yeah, how much does it cost?
LLM: $50
The user twice asks how much something costs, but the user is referring to two different things. The correct outcome is to return an answer from the LLM and not from the cache (i.e., a cache miss). Without awareness of the context of a conversation, the semantic cache incorrectly returns a cache hit. Without awareness of the context, a semantic cache will cache the first response to ‘how much does it cost’ and use the cached response to incorrectly answer the user’s second question.
Canonical’s Context-Aware Semantic Cache
In order for the semantic cache to work in a conversation, we make the cache aware of the conversational context. At Canonical, we’ve built many different technologies to address the contextual requirements of conversation AI caching.
Here’s one example. A cache is made up of key-value pairs. The keys are user queries. The value is the LLM response to the user query. When a user makes a new query, you search the cache to see if any keys match the new user query. In the Canonical cache, each key contains more than one conversation turn. By looking over a longer segment of the conversation, the Canonical cache uses context as part of its match criteria. You can think of it like language translation – the more contextual history you pull into the translation request, the more accurate the translation.
Multitenancy is table stakes for conversational caching. Developers can determine the scope of the cache and choose to have more than one cache for a conversation type. For example, a company may have three different AI personas that all serve the same use case, like booking a hotel stay. Each person is for a different hotel luxury tier. The developers wouldn’t want cached responses from one persona returned in a conversation with another persona. Instead, the developer deploys a different bucket for each AI persona.
There Are Only Two Hard Things in Computer Science
Phil Karlton said, “There are only two hard things in computer science: cache invalidation and naming things.” Caching is rich with challenges -- and rich with opportunities for innovation, especially as it is applied to Generative AI. Context caching and multitenancy are just two approaches of many that we take to make caching work for conversational LLM applications.
If you’re interested in trying out our cache for your Voice AI application (or other conversational LLM application), you can generate an API key on our homepage and get started with our GitHub repo examples. Or reach out to us! We’d love to hear from you!
Tom and Adrian
April 2024