Why We’re Building a Context-Aware Semantic Cache for Conversational AI

Problem
Large Language Models are slow
Users expect digital products to work at the speed of the modern internet. We’ve bounced off many nifty AI demos because the progress-spinner spun too long. Most users just want the product to work and have even less patience than us.
Large Language Models are expensive
Great founders are relentless about their unit economics. And investors expect high gross margins for software businesses. Even if your LLM bill is subsidized through generous cloud provider deals or you’re using fine-tuned models, the inference costs are a large line item on your cost of goods sold.
Solution
We’re building a context-aware semantic caching layer to reduce LLM latency and costs.
It’s not just a semantic cache, like the LLM cache you may find in the box with your vector database. We’ve talked to many developers who try semantic caching with a simple cosine similarity search, see the unsurprisingly poor accuracy from this context-agnostic approach, and kick the can on caching’s cost and latency improvements.
Instead, we’re building a context-aware semantic cache for conversational AI. An accurate and effective LLM cache needs to understand the context of the conversation with the user. A context-aware semantic cache requires multi-turn cache keys, named entity recognition, query elaboration, metatags, templatization, function call caching, custom cache scoping, dynamic cache invalidation, and so on – all at lightning fast speeds.
It turns out that it’s really difficult to build contextual awareness into a cache. As the Canonical AI CTO, Adrian Cowham, likes to say, it will take lifetimes of work. It’s not something you can put together in a weeklong sprint. And it’s that challenge that we find rewarding.
Conversational AI Semantic Cache Demo
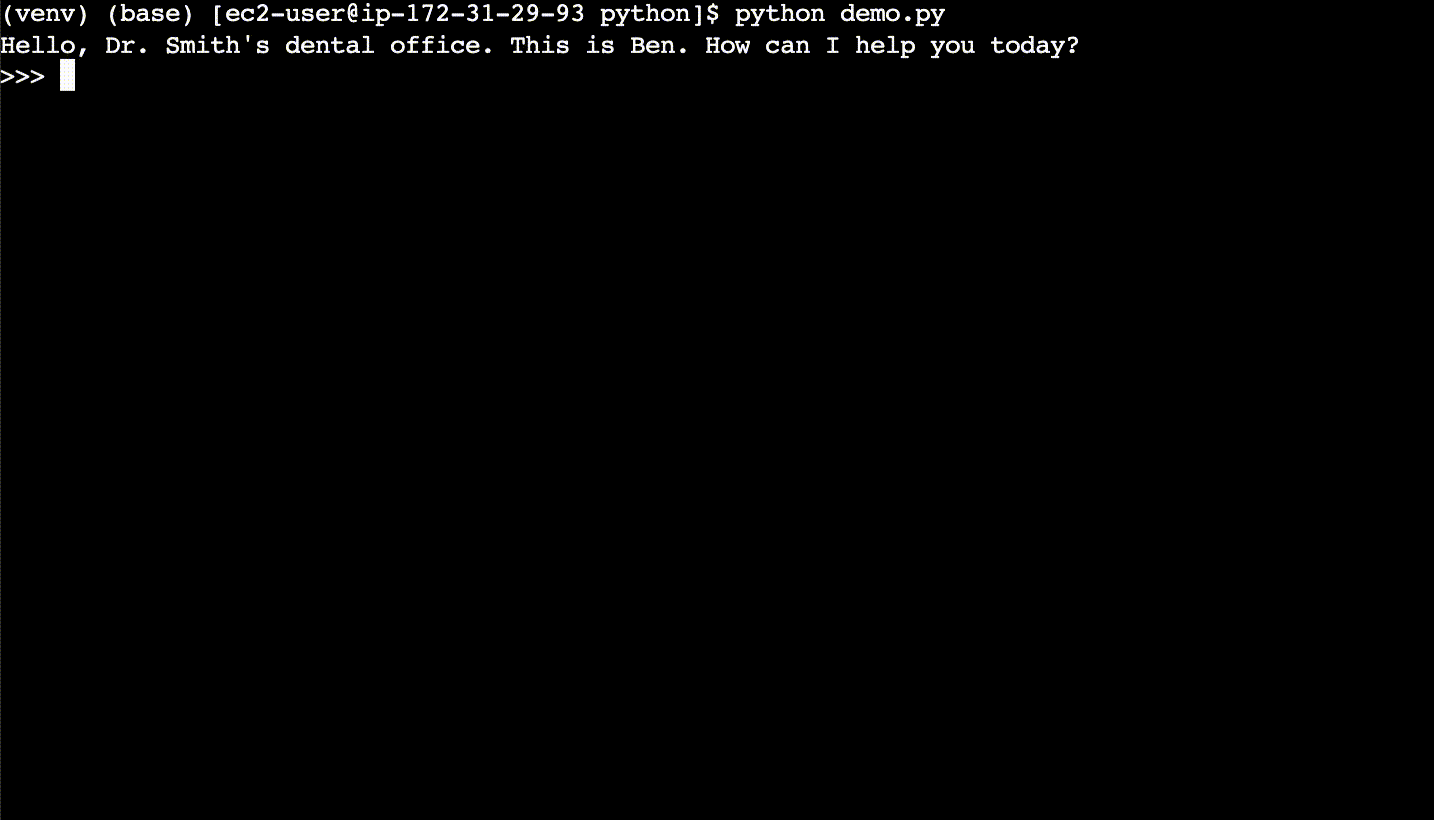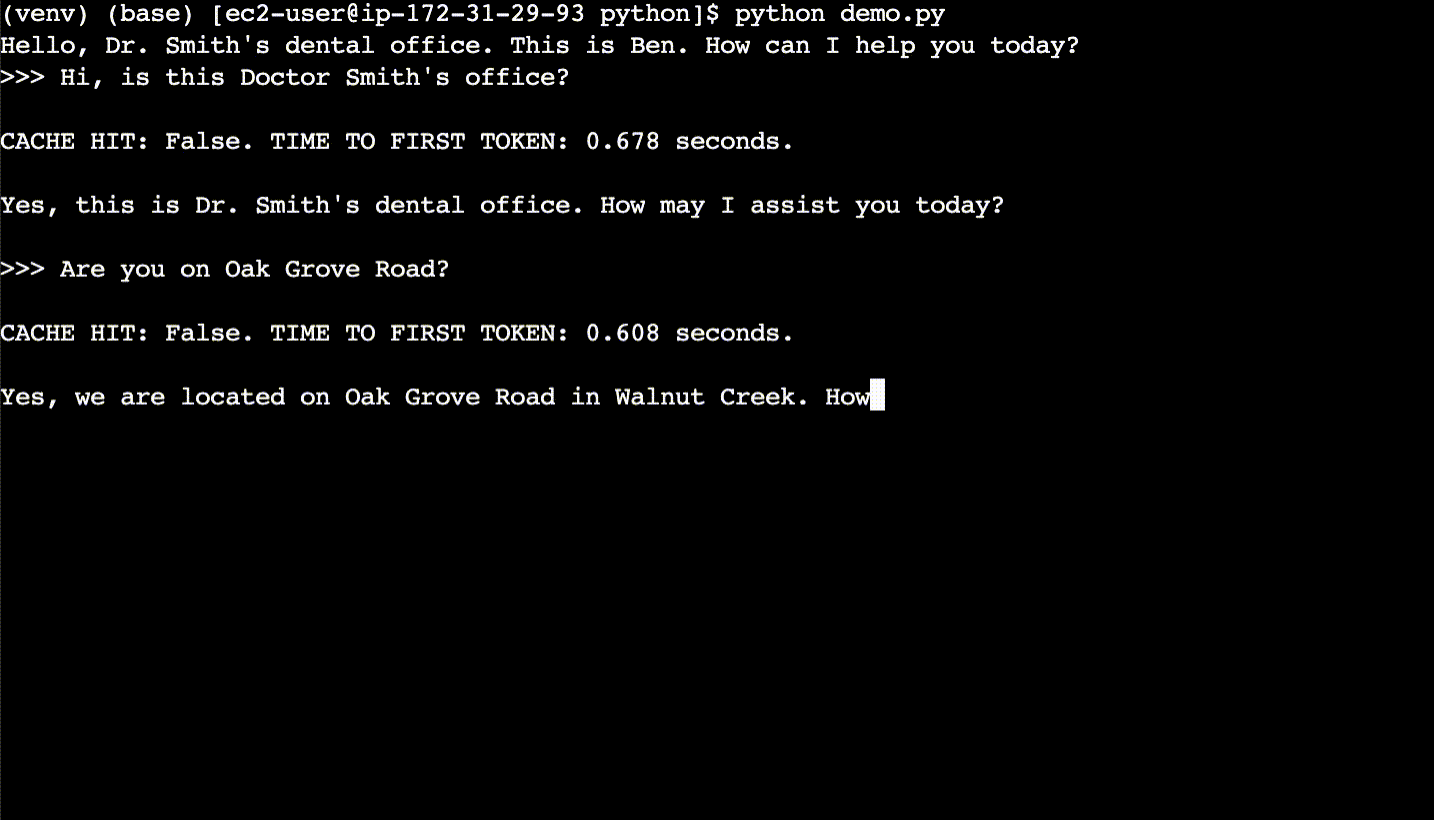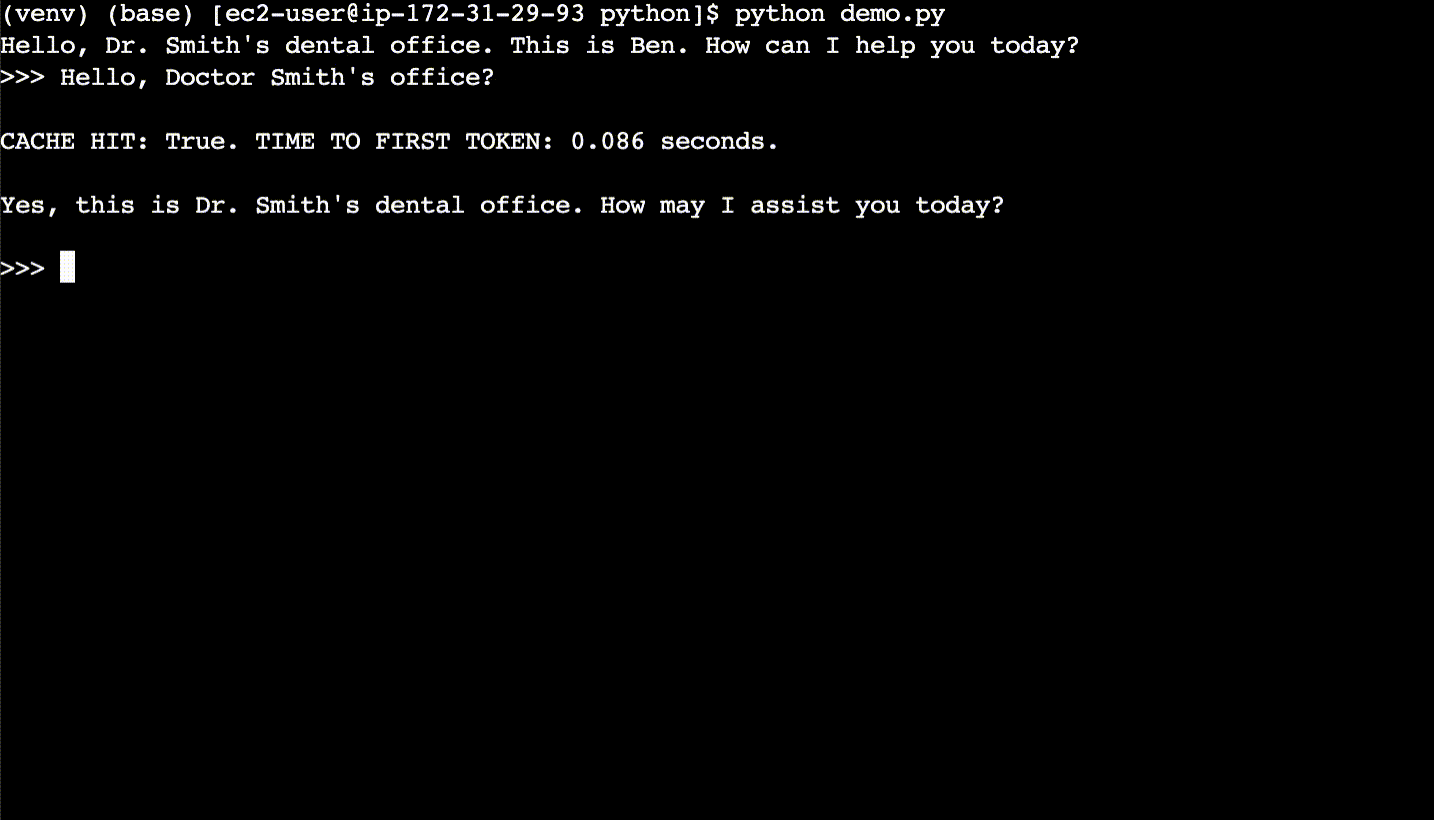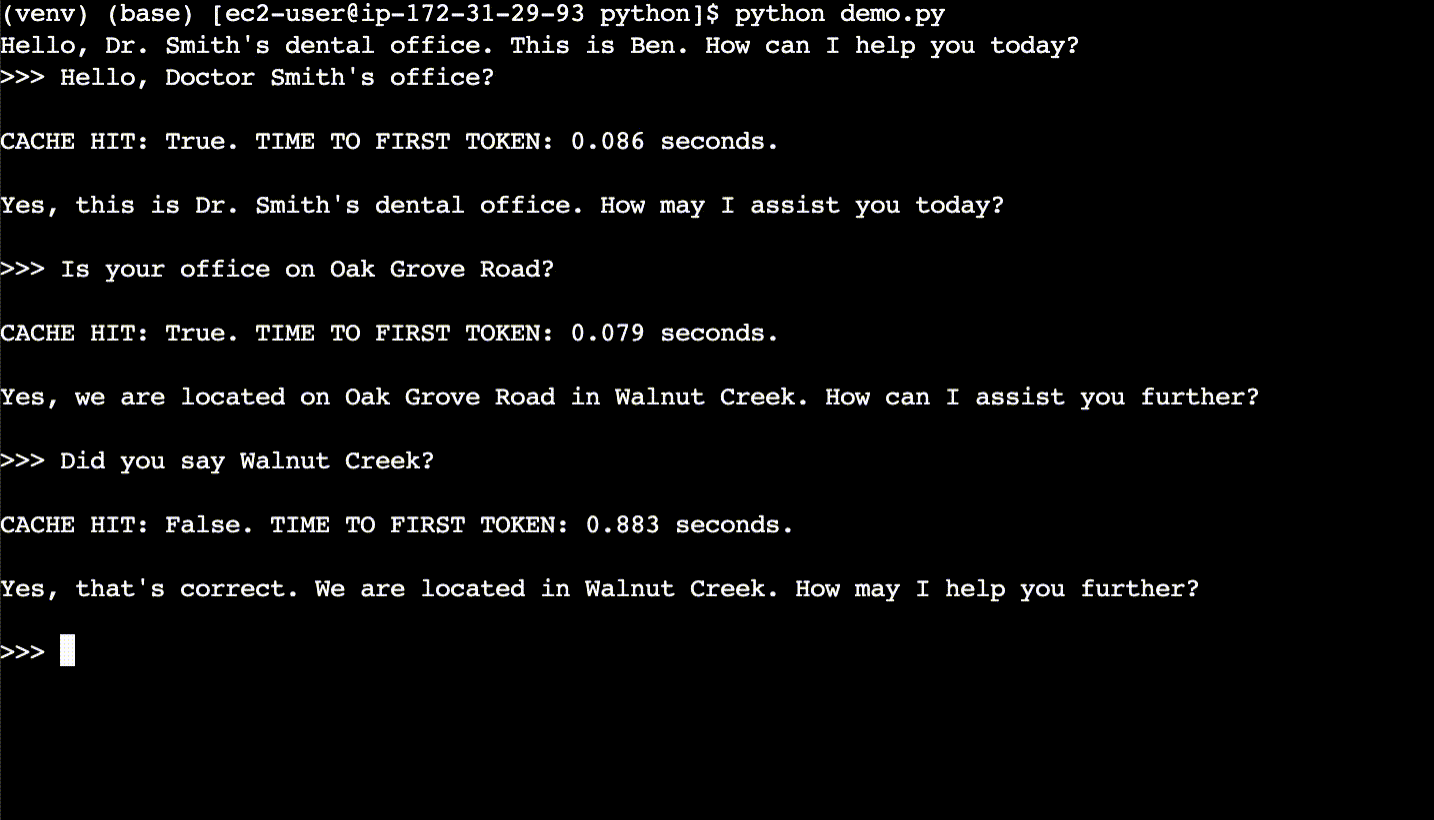
Here are the basics of semantic caching. For each user query, first semantically search the cache for what is essentially the same query – even if the query phrasing is different. If a match is found in the semantic cache, return the response from the semantic cache rather than calling the LLM. A cache hit has a faster response time and costs less compared to an LLM.
In the first conversation in the demo, the user asks new questions, the LLM responds, and the cache gets populated.
In the second conversation (after the terminal is cleared), the user asks the same questions, but with different phrasing. The responses are returned from the semantic cache and the time to first token is 10x faster.
Semantic Caching is a Pillar of AI Infrastructure
Caching is a pillar of internet infrastructure. It is becoming a pillar of LLM infrastructure as well. As we move out of 2023 (The Year of the AI Proof Of Concept), we’re seeing P&L managers scrutinize LLM API fees. We’re also seeing multiple LLM calls per user query, and that trend will continue as AI products become richer and more immersive. LLM caching is necessary for AI to scale.
We’ve initially been focused on Voice AI because latency is critical to the user experience. But developers outside of the Voice AI community have started using our cache. We’ve found that once an AI company starts handling enough LLM calls, they realize they need LLM caching. In fact, the AI companies with the most traffic, like OpenAI and Perplexity, use semantic caching. We’ve loved getting to learn from our developer customers about all sorts of interesting AI domains – from user-facing AI agents to behind-the-scenes AI security platforms.
About Us

Tom Shapland is a cofounder of Tule, a Y Combinator S14 agtech company. Adrian Cowham is Tule’s former CTO. We built machine learning models using a rich proprietary data set at Tule. After Tule was acquired in 2023, we wanted to embark on the startup journey again.
We chose to work on caching because we love working with developers and learning about what they’re building. And we love herculean, infinite challenges – like selling atmospheric turbulence-based evapotranspiration measurements to farmers or making semantic caching work in conversational AI.
Get There Faster with Conversational AI Caching
Is latency an issue for your LLM application? Do you want to prepare yourself for when those LLM credits run out?
If you're interested in trying out our context-aware semantic cache, generate an API key on our homepage for a free two-week demo. Our GitHub examples can help you get started.
Or just reach out! We would love to meet you!
Tom and Adrian
May 2024